Between Exports and Infrastructure: Linked Data Systems in 2022
Good morning, everyone. It’s lovely to be back here, especially at this time of year! I’d like to thank the organizing committee for inviting me here today. I hope that what I say will be both interesting and informative for you all. Thank you to the people who’ve worked through the logistics, from setting up the room to ordering the food, and those who’ll clean up after us. I’m grateful as well to Dorothea Salo and Marshall Breeding for listening to my thoughts as I was writing this, to Matt Miller and Jim Hahn for answering some questions, to the small group who gave feedback on a runthrough Monday, and to the multitude of others who’ve shaped my thinking along the way.
I’ll be putting the text of this talk and some of these slides on my website, ruthtillman.com, under the “presentations” section, it should be available there after tomorrow.
As Caroline said in my introduction, I work with and study library systems, both historical and emerging. I think that studying the history of the ILS and its maintenance today provides critical insight into how we build for the future… and while I won’t be directly addressing that research, it shapes how I’ve approached this topic.
When you’re used to having the tools you need, it’s easy to expect things to just work. And unless you specialize in thinking about how systems come together or study how they were made, it may be hard to identify all the things that have to get done between “we have a BIBFRAME standard” and “we can make BIBFRAME records” or “we can make BIBFRAME records” and “we can use BIBFRAME with the same degree of friction as we use MARC now.” This makes it tricky to attend a presentation where someone is talking about linked data or BIBFRAME and evaluate what they’re saying or what it means to you. I hope that this presentation is not only informative but will give you some framework for understanding where future updates fit in and how to evaluate what you hear.
The ILS in the Modern Library
The ILS (or LMS or LSP, but I’ll use ILS today) is central to many business functions of a library - especially much of the behind-the-scenes work the people at this conference do. These systems were often built around the MARC record, which ties into the acquisitions module, the item management module, the serials module, even the circulation module. Everything except our user accounts touches the MARC record, or at least a set of fields extracted from it - title, author, etc.
ILS development takes a long time and the number of such systems under active development is increasingly limited. So first I’ll tell you what I don’t expect to see. I don’t expect to see an ILS any time soon that’s built around BIBFRAME the way current ones are built around MARC. Overall, I think that’s a good thing. We should be figuring out what functional benefits we could actually get from BIBFRAME and building for that.
To paraphrase something Marshall Breeding wrote 16 years ago, modern library systems aren’t just the ILS - they’re many systems, knitted together. Our ILSes have WebServices or APIs that let us build or plug into other external systems. We even have library-specific data transfer standards, like Z39.50 and NCIP.
When many of us visit our public libraries’ catalogs, we’re not seeing the OPAC that comes with the system - instead we’re seeing something like Aspen Discovery or BiblioCommons. Most academic libraries use some kind of external discovery system, often Summon, Primo, or EDS. Penn State and other comparatively well-resourced universities have been creating custom catalogs using Blacklight or VuFind software.
And when we create, reuse, or enhance MARC records? Most of the time, we’re not doing it within the ILS—we’re doing it in Connexion or in MarcEdit.
I’d argue that what an ILS needs from our bibliographic records is a record ID and some basic metadata … probably the title, author, and date, maybe edition.
So does BIBFRAME need to be integrated into the ILS? Yes, but maybe only in the way that Connexion, ILLiad, or the Catalog integrate into our systems.
What Do We Need?
So then, what do we need for a BIBFRAME integration?
- A way to catalog in BIBFRAME and supply appropriate metadata to the ILS for its reuse
- A way to get good BIBFRAME out of older records
- A way to turn BIBFRAME into a meaningful discovery experience through linked-data aware querying - or at least, to do something more with BIBFRAME than we could do with MARC
- A way to share records, or the statements that make up records, or create records through aggregating such statements - and in the long short-term, to share records in a way that supports both MARC-using and BIBFRAME-using libraries. One that’s not re-enclosed, turned into a walled-off pay-to-play space by vendors.
I’ll start by talking about what we do have now, then what we don’t have, a bit about other linked-data related efforts in libraries, and close by sharing my thoughts on what ordinary folks can do now.
But before I do that, I need to share one of my concerns with the path to BIBFRAME implementation. We’re part of the way to figuring out what that looks like, we have some things in place, and we have ways of filling the gaps. But it would be possible to create BIBFRAME and send it to the ILS, transform our old MARC, send BIBFRAME to discovery systems, and share records and yet to do all that in a way that does not provide significant advantages over a MARC-based system.
Right now, for example, there’s a lot in bibliographic and authority records which we aren’t actually using in our catalogs and discovery systems, either because of data completeness or design choices and developer time. So it’s entirely possible we could end up in a place where catalogers are told that they’re doing BIBFRAME or linked data, but we’re all just working in a jury-rigged Frankensystem which doesn’t provide significant improvement over what we’re doing today. We need to consider what’s a meaningful use of linked data and whether it can be operationalized in ways that provide significant enough advantages to merit such a massive transition.
Our Objects in Cataloging
…and speaking of what’s meaningful, while the means have changed, I actually think our objects in cataloging and catalog design still primarily align with those Cutter spelled out on page 10 of his 1876 Rules for a Printed Dictionary Catalogue.

Everything else we do is a bonus. And at a time where budgets and staffing numbers are being cut - if we’re going do that extra work, we need it to be worth that extra effort. So you could say I’m agnostic about linked data. I see some things which are fun to think about in a blue sky way. I think we could benefit from moving off MARC, which has served its purpose very well but can only be stretched so far. I’m not yet convinced that a shift to BIBFRAME will help us achieve the best outcomes for the 99% of users who are not going to do deep relational dives. But let’s take a look at where we are and what we do have.
What We Do Have
Cataloging in BIBFRAME
First, we need tools for cataloging in BIBFRAME and supplying appropriate information for ILS reuse. This is the area in which I’d say we’re closest to the tooling we’d need for BIBFRAME integration. If you’ve been following BIBFRAME news at all, you’ve probably heard about the BIBFRAME editor Sinopia, part of the LD4 project. More recently, the Library of Congress released their Marva editor, which Matt Miller wil be presenting on later, a replacement fortheir older BIBFRAME editor. They even have a version open to the general public for experimentation at bibframe.org/marva/.
One of the most important aspects of any BIBFRAME cataloging tool is that it will not require you to be thinking about BIBFRAME. That’s fundamental. Even if we changed over to using BIBFRAME tomorrow, only a small percentage of catalogers in the room today will need to understand its technical details.
Instead of thinking about everything as BIBFRAME encoding, the way you might think about a MARC field, indicator, subfield, etc., you’ll be cataloging based on RDA concepts. So, you’d navigate to the Creator of Work field, choose Person, get the person’s LC URI (which auto-populates the authorized form of their name), and choose the relationship designator of author from the dropdown - or director, librettist, etc.
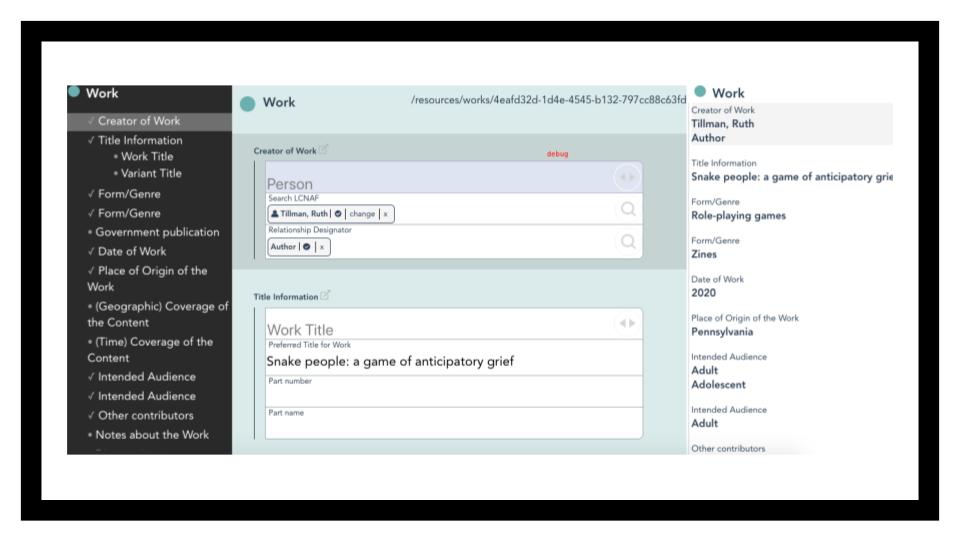
Having used both Marva and Sinopia, I think that Marva supports “BIBFRAME cataloging without thinking about BIBFRAME” especially well. Not only does its sidebar make it easy to navigate through a record, it shows you a live preview of your record as text. Both Marva and Sinopia are set up to query controlled vocabularies - you don’t have to go find the term and its URI independently or type it and worry about typos, though each editor allows you to click through and explore the term on its original site.
ILS Reuse
And we can’t just have a good cataloging tool - we work in systems. It’s at least necessary to hook some bibliographic metadata into our ILSes.1 And for the older ones, this will need to be MARC.
Since the last video they’d posted on the Sinopia to ILS export process was at the end of 2021, I’m not entirely sure where Sinopia stands on that work, but at the time they’d made significant progress in sending records from the editor into various ILSes, from the newest to older ones like Sirsi Symphony. Jim Hahn has designed a pipeline for Marva to Alma and with the Library of Congress’s announcement that they’re adopting FOLIO, I anticipate there will be strong support for Marva as an editor for FOLIO.
Record Transformation
As for getting good BIBFRAME out of older records, there has been some progress in the publication or publication-ish of non-queryable BIBFRAME and other linked data derived from our catalogs.
Zepheira’s Library.Link, now part of EBSCO’s NoveList, will take your MARC records, create BIBFRAME data and several other forms of linked data records, and publish it to the web. They have done an excellent job implementing Schema.org, a linked data standard specifically intended for search engine results. In particular, they combine bibliographic data with administrative data about the holding institution and its branches so that each record has holdings-based geocoordinates - meaning that search engines can display location-based results.
"@type": "BorrowAction",
"lender": {
"@id": "http://link.dclibrary.org/#TENLEY",
"@type": "Library",
"image": [
"http://link.dclibrary.org/static/img/share.jpg"
],
"location": {
"@type": "Place",
"address": {
"@type": "PostalAddress",
"addressCountry": "US",
"addressLocality": "Washington",
"addressRegion": "DC",
"postalCode": "20016",
"streetAddress": "4450 Wisconsin Ave. NW"
},
"geo": {
"@type": "GeoCoordinates",
"latitude": "38.9476208",
"longitude": "-77.0799279"
}
},
"name": "Tenley-Friendship Library",
"openingHours": [
"Mo, 09:30-21:00",
"Tu, 09:30-21:00",
"We, 09:30-21:00",
"Th, 13:00-21:00",
"Fr, 09:30-17:30",
"Sa, 09:30-17:30",
"Su, 13:00-17:00"
],
"telephone": "202-727-1488",
"url": "https://www.dclibrary.org/tenley"
},
"target": {
"@type": "EntryPoint",
"actionPlatform": [
"http://schema.org/AndroidPlatform",
"http://schema.org/DesktopPlatform",
"http://schema.org/IOSPlatform",
"http://schema.org/WindowsPlatform"
],
"urlTemplate": "http://link.dclibrary.org/portal/Liliths-brood-Octavia-E.-Butler/-WOd2Dj3OBQ/borrow"
}
},
This is great, because just making our resources discoverable in search engines isn’t that helpful-if we’re in Arlington, we need to see results local to this region, not to Arlington, Texas, or somewhere like Penn State that might have better search engine optimization.
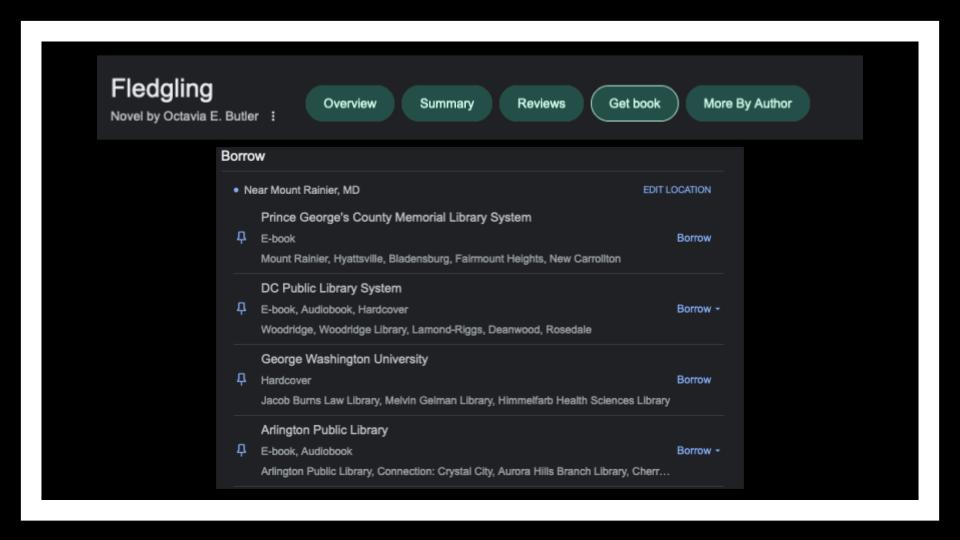
The other benefit that I see in Library.Link is the improved use of authority records to aggregate work creators as both creators and as subjects.
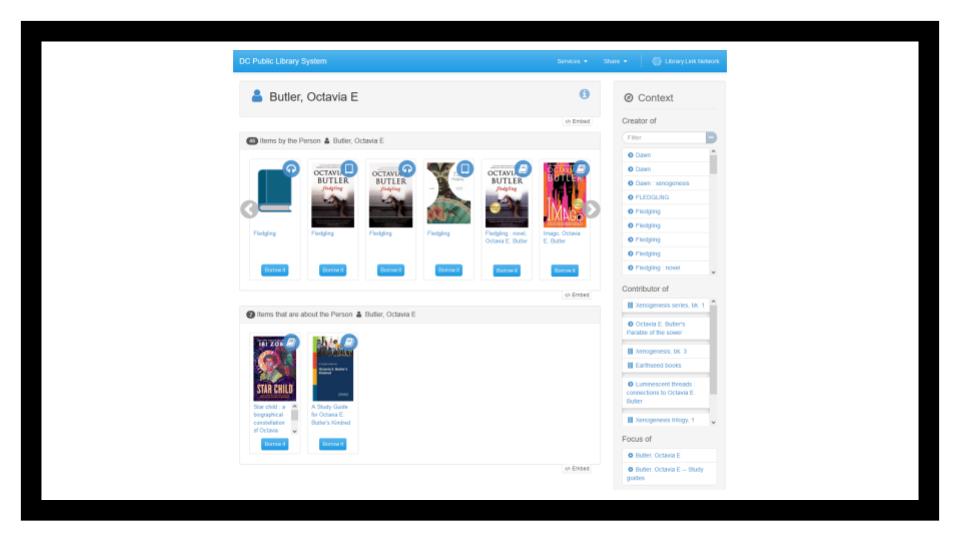
This, for example, is a page for Octavia Butler in the DC Public’s Library Link. It brings together works for which she’s the creator with works for which she’s the subject. It’s pretty cool and meant to power other kinds of things, vs. be a front-facing record.
It’s also all derived, which means that it’s done record by record. Even in this one library there are six different records for Fledgling, 5 of which appear on this screen - in what’s meant to be a widget you could embed in a webpage or email. Derivation can only go so far when you aren’t also adding in modeling that groups the same Work together.
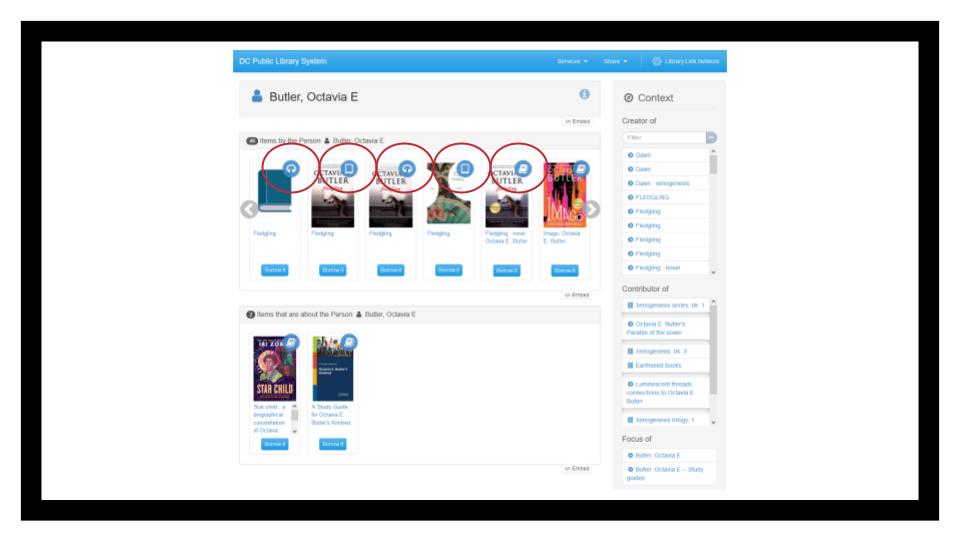
You may be able to see the icons on each cover, indicating which are physical books, which are ebooks, and which are audiobooks. Clicking borrow takes you immediately to that book’s record—but not modeling it in a work-based way means that you get this weird discovery experience. That’s what we have right now in MARC, a fast path to what a particular format, but also an experience that confuses patrons. (possible aside that I sometimes get emails and calls about why we have 2 or more records for the same edition of a book, because of ebook formats, acquisition history, or leasing.)
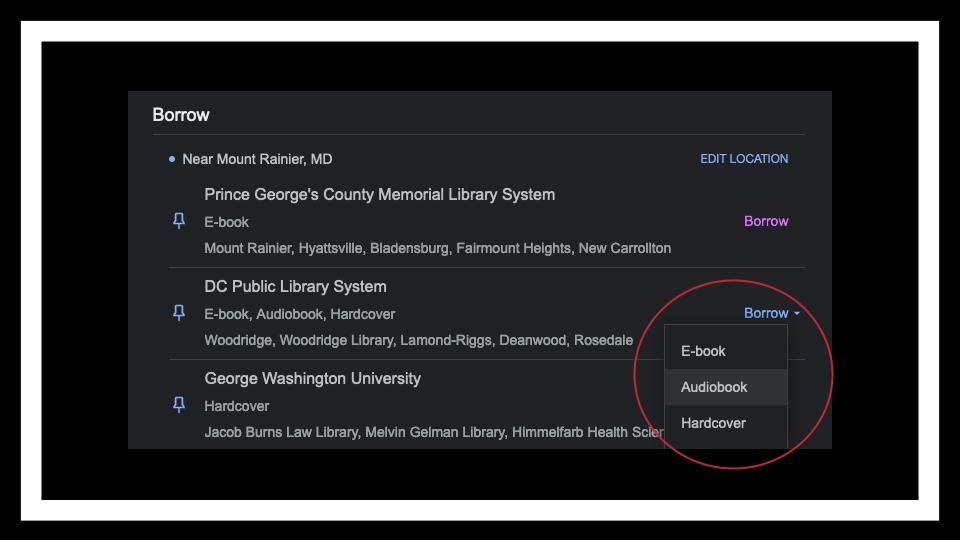
Between Library Link and Google, however, they’ve got it sorted out better. So, while the widget is a bit overwhelming, when you’re actually looking at borrow options in your search results-clicking borrow shows you three format options, directing you to exactly what you’re trying to use.2
And speaking of its being derived - I’m not sure what role linked data per se is really playing in these systems that can’t be derived from MARC…since that’s what’s happening here. That doesn’t mean they’re not interesting and innovative projects. But our use of controlled terms - which is certainly improved by the URIs that Sinopa and Marva ingest - would allow us to build a very similar page by processing our MARC into some other format.
I don’t think anyone working on BIBFRAME and the like wants to stop with just this kind of project. But it’s important to be aware of the point at which such systems make the transition to being something that can only be done with linked data and what we could do ourselves if we had development capacity.

Shared Data Pilots
And last on my list of things for which work is underway is data sharing. There’s a lot of reasons why we all keep our own database of all our MARC records, but when you think about how many libraries are keeping their own copy of the same records with minor variations, it’s certainly not the most efficient way to approach bibliographic description. This becomes even more important with something like BIBFRAME, whose records are much larger than the compact MARC standard.
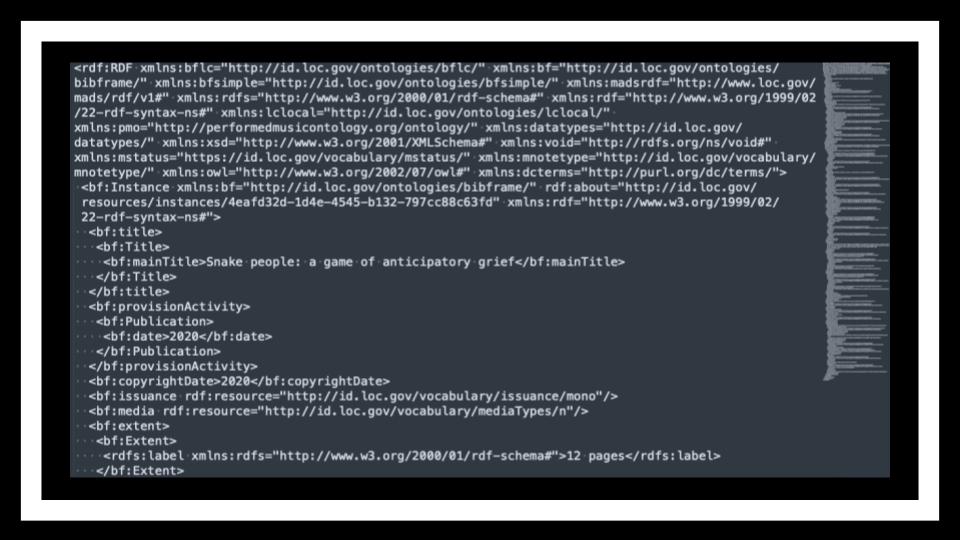
All the extra text added by the XML around each statement, for example, takes up space if we’re handling the data in its RDF/XML syntax, other formats have other challenges. N-Triples requires full URLs, though “Turtle” (TTL) is a bit smaller.
Do we all need to store the same OCLC numbers, place of publication, edition statement, title, contributor URIs, etc.? Can the directly transcribed fields, along with identifiers like ISBNs, OCLC numbers and LCCNs, be stored in a shared environment, with individual libraries having more control over things like subject analysis, notes, and other augmentations?
In the sphere of commercial ILSes, Alma offers Network and Community Zone records, which allow you to both reuse the record and, if you have a plugin, enhance it with a few local fields. I am not sure how FOLIO has or will be managing similar things.
For BIBFRAME, the SHARE-Virtual Discovery Environment (VDE) project has done significant work toward building a shared database which also allows institutions to reuse each other’s BIBFRAME statements-basically the individual fields of a record.
This is more than a technical test - it’s test of politics and processes. Conceptually, institutions may be able to agree on what should be shared vs local, but how well will this play out in practice? Who will control it? I’ve heard about edit wars in Alma community zone records, for example of one cataloger updating subject headings to their deprecated forms.
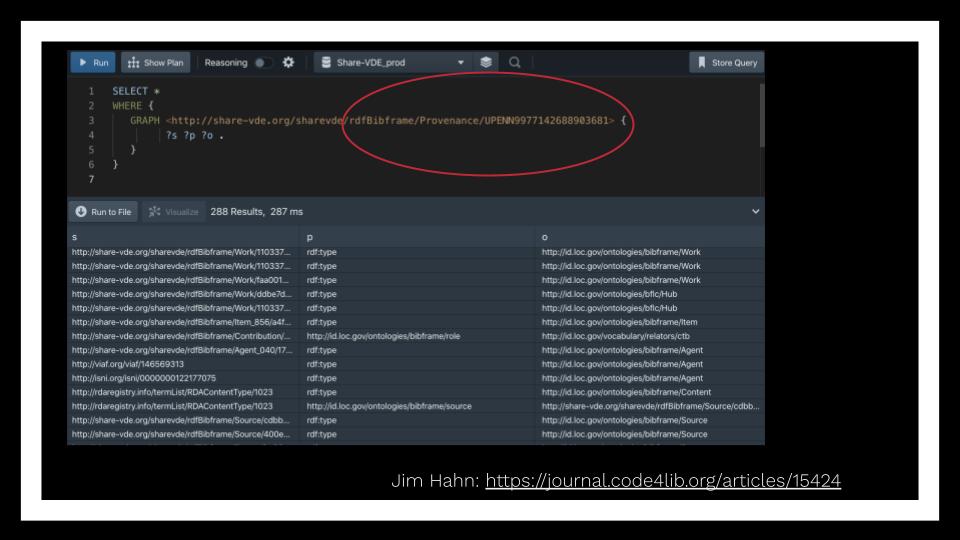
In SHARE-VDE, statements have additional administrative information about their provenance, as shown in this image from Jim Hahn’s Code4Lib article on data enrichment and SHARE-VDE, so you can distinguish that one came from Duke and another from, say, Yale. With additional system design, one might use that provenance information to exclude all subjects from the institution with a cataloger whose changes we don’t want in our systems. Right now, though, the provenance is real but any system-level use is hypothetical.
And then how does one expand the infrastructure for more libraries, particularly those who have the fewer resources to set up their own systems? How would we keep vendors from laying claim to these records the way OCLC does to our MARC? What tools would we need for catalogers to take advantage of shared data and linked data’s statement-based nature to build their own records by importing bits of data from various sources? It’s going to take years to sort out and while the work is underway, it’s early days yet.

To recap what we do have: we have record creation tooling which has made significant strides toward being able to integrate with an ILS. We have methods of turning MARC into linked data, most usefully Schema.org, which is being used to enhance discovery outside the library. And we have projects testing how BIBFRAME can be implemented in a shared system, early steps toward answering big questions.
What We Don’t Have
Meaningful Discovery

While there have been a lot of experiments for discovery, I haven’t seen anything yet which I’d consider a meaningful discovery experience which realizes the potential of linked data, or stated another way, that is more than we can do with MARC. There has been some good work done to surface relationships, and some good work like Cornell’s project to create enhanced author discovery pages using linked data sources:
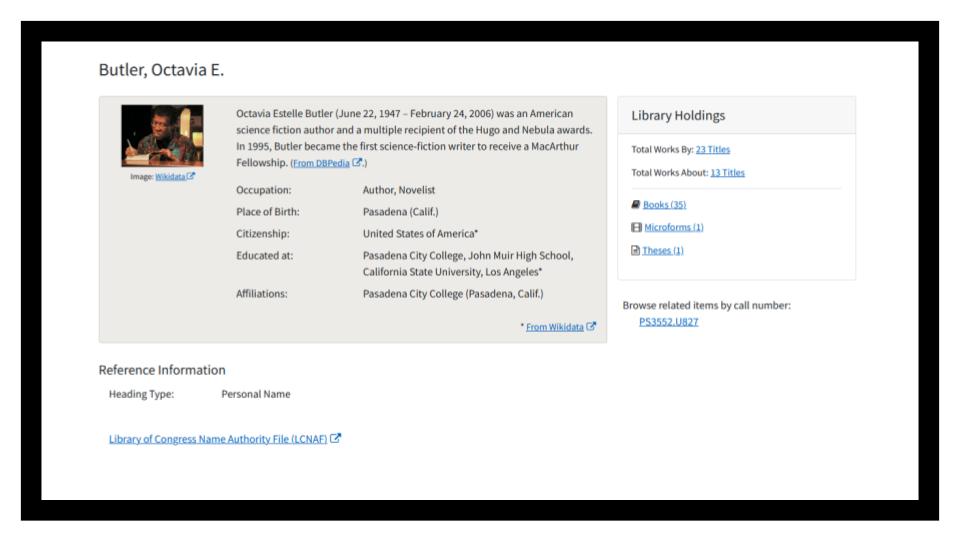
I really like this! But, as I said before, most of it is simply taking advantage of bibliographic data that wasn’t being fully utilized as MARC. It then stirs in a little external linked data.
What would discovery that moves beyond MARC into linked data look like, then?
Let’s walk through one hypothetical:
Suppose I want to look for works by people who won a particular award, like the Inkpot? While we might have information in a bibliographic record about awards won by a particular film or book, e.g. Perilous Gard is a Newberry winning children’s book - we don’t tend to store that information in our authority records. That’s exactly the kind of thing linked data is meant to allow us to do without having to duplicate that information in our own systems.
I’ve done this kind of query - but I had to do it in phases, writing and running separate scripts. It took detailed knowledge of the systems and of the kind of data I was looking for. I starting by getting information about who won the award, then finding the authorized form of their name, and then query our catalogs. Wikidata is one example of a place where such data can be found - both information about awards won and LC authorities.
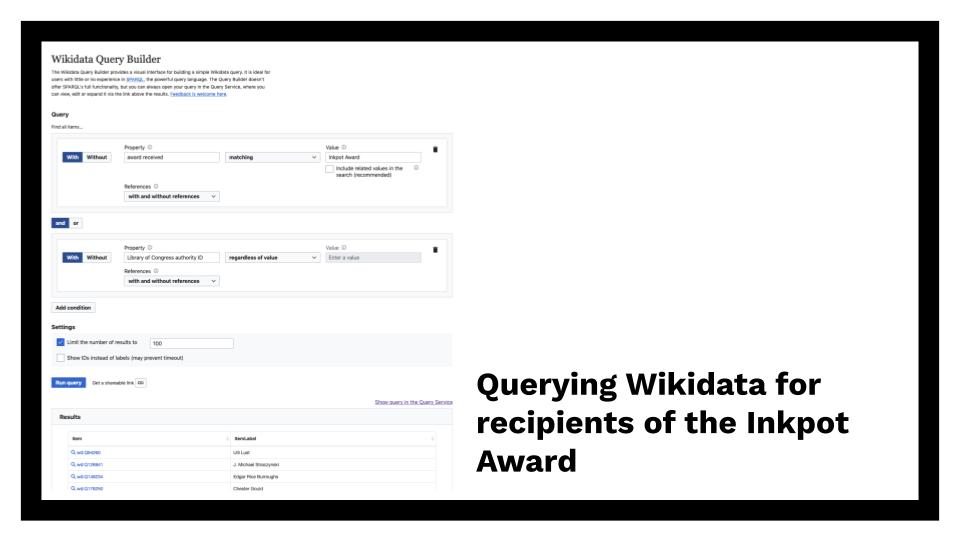
So to make such a query, I’d start in Wikidata, getting the records for people whose records state that they won the Inkpot Award and who have an LC Authority ID. This is an example of how the new query interface would help me build such a query. However, I’m more comfortable in the old interface, where I can build a SPARQL query along these lines:
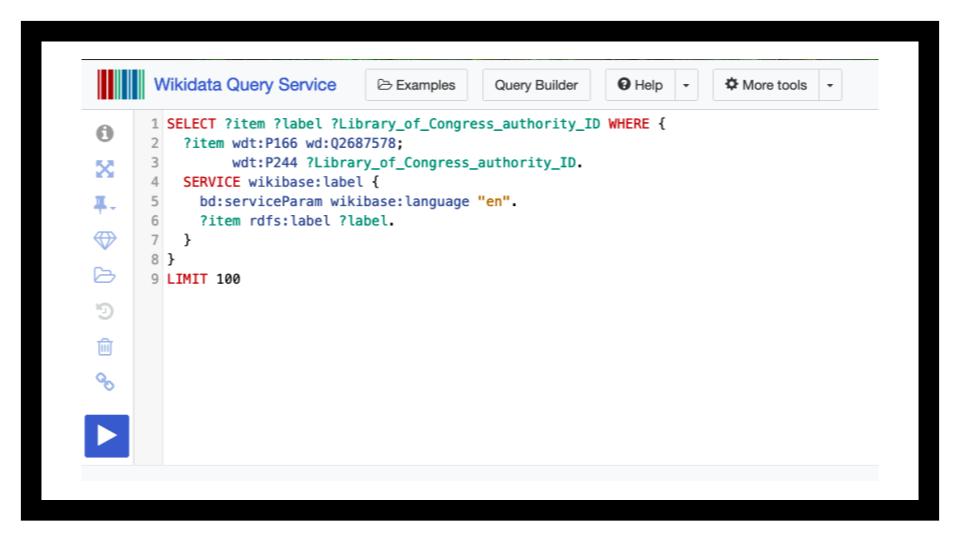
This can be read as select item, item label, and LC authority ID where the record states that the person has won the inkpot award AND the person has an LC authority ID. I could also get other information, if it exists, some of it the kind of info we keep in MARC authorities, and some that we don’t.
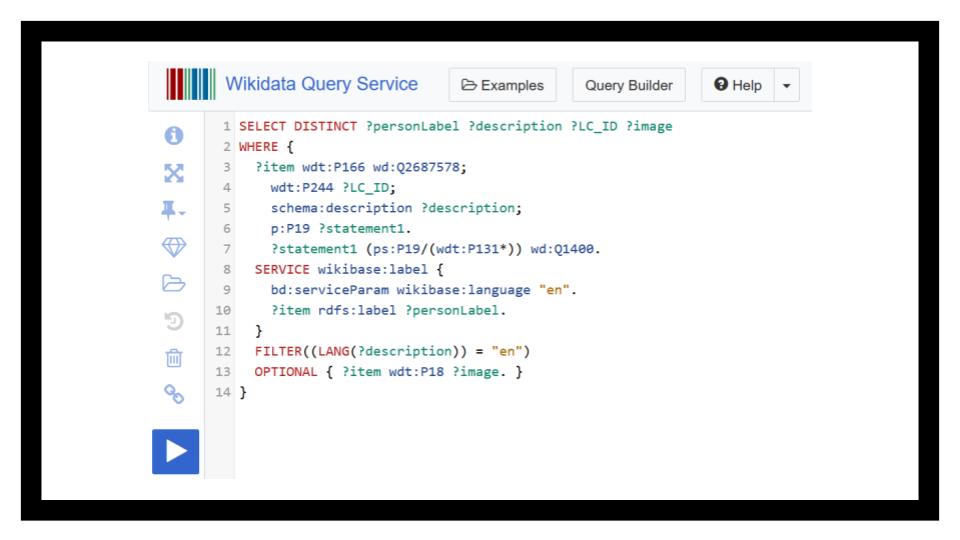
What I’m going to do now, because I’m interested in Pennsylvanians, is select everyone who was born in Pennsylvania or a location nested administratively within Pennsylvania.
So here’s some results: https://w.wiki/5oaW
I would then query a NAF download for the authorized form of each name, which I could throw into its own file.
Next, I would run a script testing each authorized name in our catalog to see if we had any results.
I can compile all those results into a list, with canned links to search for each person’s works! When making this page, I went back and grabbed other info out of the person’s wikidata page, like their image and description.

All this took testing, refinement, and specific measures to avoid crashing any of the systems involved. My coworkers would not have thanked me if I’d crashed the catalog for my little experiment. So, there are understandable reasons why we don’t have this!
Triplestores and SPARQL endpoints require a lot of resources. A poorly designed query can crash them. Too many users at once can crash them. Our catalog gets 1500 to 3000 visits a day. If the Library of Congress had a SPARQL endpoint that we queried live each time, we might crash it all on our own—let alone if you add in all the other libraries who’d be doing the same. That’s not to say I don’t love what the folks at ID.LOC.GOV have been doing - especially the incremental download options. It’s really cool and it doesn’t yet scale to live querying.
And even user-friendly query design interfaces, like Wikidata’s, require a certain amount of expertise to use for more than a basic query. The interface needs to convey what’s possible, to let the patron know that they could search for works by people who’ve won an award, or who were born in a particular location, or a combination of the two. Then it needs to support them in building that kind of query along with myriad other kinds of queries. And then it needs to return the results in a timely fashion—I’ve hit plenty of timeouts in Wikidata’s query service, almost certainly because I wasn’t querying efficiently enough for the amount of data involved.

Good Data

And speaking of data - we need a way to get good BIBFRAME out of older records. Dorothea Salo spoke about this in 2015 and it’s still an area in which we struggle - both in terms of quality and completeness.
How much time and energy can we dedicate to good data? We are working on very specific things, but on an enormous scale - information about all knowledge production and its outcomes, including information about those producing it. For example, my mother has a NAR because she published a book. But she wasn’t well-known, and now she’s dead. Nobody but me was keeping tabs on her. The only reason her record has a death date is because I’m in the field and couldn’t stand seeing it left open-ended.
Merging and Disambiguating Entities
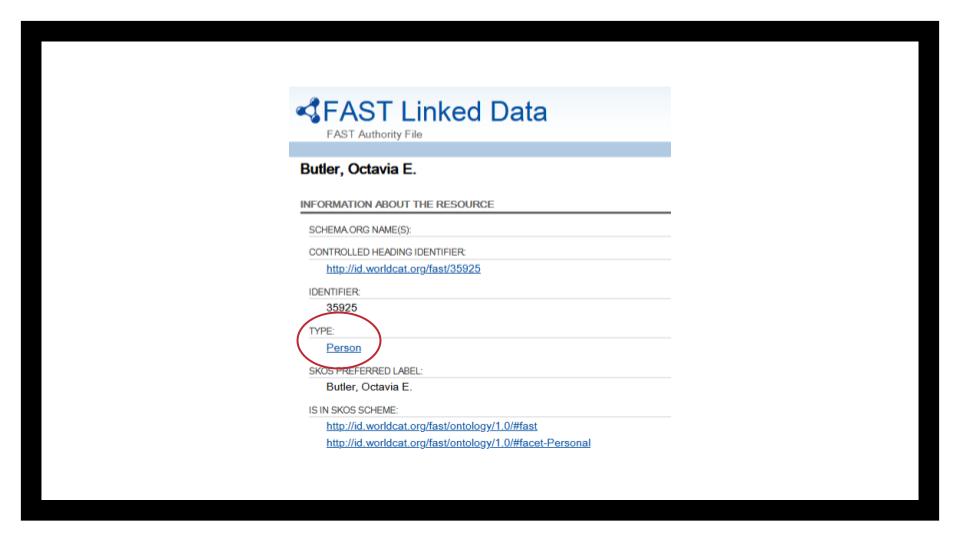
Linked data also introduces a challenge of identifying the Type of thing being described. When we’re using text, it’s easy enough to just write “Butler, Octavia E.” or “Quilts” and group all those things together, even when they’re coming from different vocabularies - so long as the text is the same.
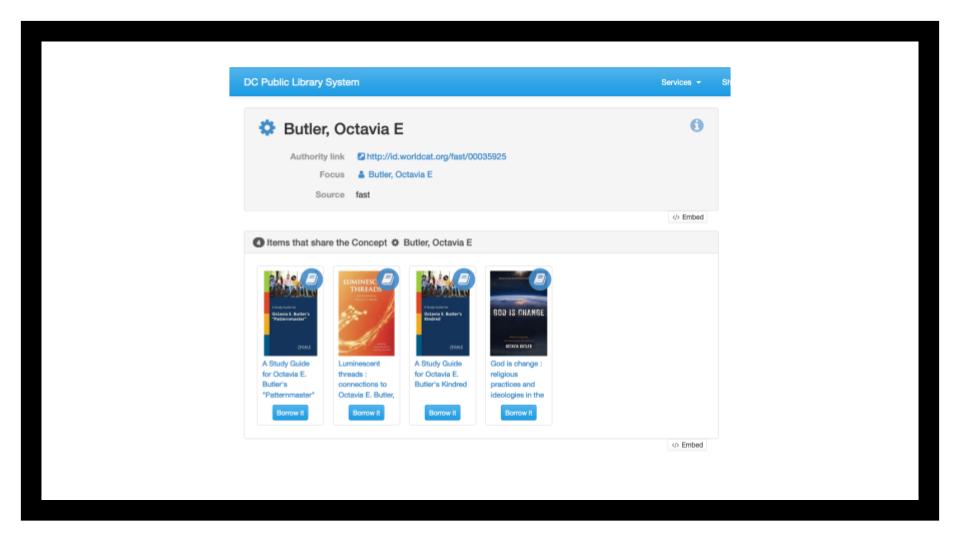
But in this example, you’ll notice that we’re only looking at a tiny subset of works about her. Because this system parses FAST heading as being for Octavia Butler, the Concept (vs the Person), it’s not been reconciled with the entry we saw earlier.

Now in FAST itself, she is a Schema.org Person - so who knows where the disconnect is coming in. Systems are hard.
We also need ways to break things apart. Even those not working with linked data may encounter this when consulting sources like VIAF which aggregates items from many authorities. Not long ago, for example, I noticed that VIAF was combining authorities for Paul Marius Martin the French latiniste and Paul Martin the Pennsylvania poet, probably because both were born in 1940.

As we scale this up, besides tools for creating data we’re going to need tools which spread out the work of saying “this is the same thing” or “these are two different things.” I know that SHARE-VDE has been working on something for this, called J. Cricket, but I’m not sure whether it’s in “wish upon a star” prototyping or closer to a “real boy” deployment.
RDA and Data
We’re also in a nebulous place when it comes to the new RDA. My understanding from RDA and BIBFRAME updates I’ve attended is that the new RDA is best suited for BIBFRAME vs. MARC. This complicates its adoption for libraries that don’t plan to be moving off MARC any time soon. Moreover, it’s a paywalled standard, locking out those who are less likely to have the resources to pivot to BIBFRAME until it’s fully integrated into the systems they already use.
I think the new RDA is not likely to have a major impact on BIBFRAME adoption - if anything, it’ll be the inverse, but I do worry that the time we all have to spend getting to know a highly-complex, proprietary standard is taking away from other data work we could be doing. To refer back to Cutter - I’m not sure whether tangling ourselves up in concepts like “appellation of expression”: “A nomen that is used within a given scheme or context to refer to an expression” is furthering our mission to help people find the works they’re looking for. In my opinion, we’d benefit more from simple enhancement work done on records and authorities.
There has been some work to make RDA less locked down and proprietary, like that the RBMS Bibliographic Standards Committee did on their Descriptive Cataloging of Rare Materials RDA edition. Not only is the guide open to all, its layout and language are more approachable than the Toolkit’s. This is necessary if we’re going to make our descriptive future more inclusive, not enclosed.
Collaborations Outside Our Systems
But inclusion isn’t just about opening our standards, it’s about engaging with others. Over the last two decades, there’ve been many failed attempts in the cultural heritage sector to bring other people into our systems, or even maintain experimental projects that rely on sustained librarian engagement. Timebound projects, like transcription work, which can be facilitated through events seem to have more success, but many of us can recall other attempts like the great folksonomy or “social cataloging era.” It turns out that if you build it, they will not, in fact, tag.
Over the last 5 years, the PCC has made several forays into collaborations with related communities and I think their approach shows some promise. First, from 2017 to 2019, they explored collaboration with ISNI. This was more of an experiment in someone else’s closed system than a truly open one, but it was a chance to learn about how another community, one that’s dedicated to disambiguation, handles the same kind of issues we do. More recently, there’s been the PCC Wikidata Project, which ran from September 2020 to the end of December 2021. Unlike ISNI, Wikidata has a low barrier for entry - it doesn’t even require an account, although they’re encouraged - and thirty-one percent of pilot institutions, nearly a third, were not PCC members.

What I find promising about both these efforts is:
We’re seeking out existing, engaged communities which have clear guidance for participation. Creating a robust project from the ground is hard work. We should avoid trying to reinvent it when possible. ISNI has the advantage of being spun out from an ISO and having some traction already in national libraries. Wikidata benefited from the already robust Wikipedia community, although it inherited many of that community’s problems and biases.
We’re finding communities with shared interests. For ISNI, we share their goal of creator aggregation and disambiguation. They’re just working at a larger scale and basing their systems on 16-digit identifiers vs. the textual strings we use. Working with ISNI gives catalogers a preview of what it might look like to work in an identifier-centric system, not a textual one. For Wikidata, the motivation is robust entity description to support discovery, something that we aspire to in our own systems but haven’t yet managed to implement. Like ISNI, they describe a wider range of creators and also care about disambiguation. Like us, they prefer citations/references for statements made in the records.
These projects can integrate into our existing workflows. In Penn State’s Cataloging and Metadata Services, our group kept going with Wikidata after the pilot wrapped. Some of the work we do is based on what comes up in day-to-day cataloging. For example, the cataloger who does ECIP for Penn State Press will simultaneously establish a NAR and create a Wikidata record for a new author, which he’ll then update with the right identifiers when appropriate. We also work on projects with Penn State or Pennsylvanian connections, but I think it’s very important that one can create or augment records alongside one’s daily work.
There are frequent talks about Wikidata itself, so I’m not going to go more in depth on the system/projects one can do. What I think is most relevant here is that it’s a robust community of its own and we’re not trying to drag anyone (except maybe each other) into working in it.
And what matters if we’re going to continue creating and editing Wikidata records it is figuring out what about it is useful for our work and what isn’t. What kind of work should be done there? What might we reuse? What kind of work should we still do in our own systems—local or national? These are the ongoing conversations happening between PCC, LD4, and Wikidata community members.
Evaluating Where We Are
I’ve tried to structure this talk not just to update you on where the system elements necessary for BIBFRAME adoption are today but to give you a framework for evaluating presentations you see going forward. If we revisit those four points, where are we on each?

- There’s been a lot of progress on tooling to catalog in BIBFRAME and send that data to one’s ILS.
- We can get BIBFRAME out of older records and even enhance it, but it’s only as good as the record it comes from.
- Most BIBFRAME discovery systems so far don’t offer much more than we could do with MARC, their main improvement is in doing the things that we weren’t doing with MARC or integrating external sources.
- There’s work underway on sharing records and resources, but it’s still early days.
What Else Can We Do?
So if we’re at an institution that doesn’t have the capacity to move into BIBFRAME until it’s much more fully systematized, what can we do?

First, BIBFRAME isn’t the end-all/be-all of linked data and linked data isn’t the end-all/be-all of descriptive work. As I mentioned before, Wikidata has a very low barrier to entry and there are quite a few trainings available out there. Each of us has specialized knowledge and institutionally-specific information which might be valuable contributions. Consider starting simple, such as by augmenting records for people connected with your institution or related to your area of specialization. And there is a lot of descriptive remediation that can be done in our existing records - everything from fixing data errors to addressing bias, harmful language, and other practices that affect our patrons now.
Second, MARC is under-utilized. You don’t have to wait for BIBFRAME to enhance your records or query your data. If you have developer capacity, you can do more with authorities than most of us are doing in our catalogs right now. Think of Cornell’s author page, or ensuring your subject cross-references are working well. Or we could generate canned links to searches by related authors by identifying people who’ve coauthored with an author on another record, or who’ve created works which are classified using the same subjects. And if you’re researching on your own, you can still use tools like MarcEdit, PyMARC, and OpenRefine in combinations to ask questions of your data that may not be supported in your vendor’s reporting tools.
Third, start thinking relationally. I don’t just mean RDA or linked data relationally, think bigger than that. I don’t know if or when we’ll ever see true linked data used to its full potential. But the concepts of linking and relationships serve us in both our descriptive work and, I think, in our everyday lives. We live in a world of more connections than we could begin to express in a record. As we build and design systems, and as we describe material, and as we engage with those in the world around us, if we keep that relationality in mind, it will, I think, lead to richer experiences for all of us.
Last month, I happened across the following quote from Bruno Latour, which I think sums up the nature of the systems we work within.

Whether technologically or socially, progress looks a lot smoother in retrospect than it does when you’re living through it - and it never stays in one place for long. What we do doesn’t have to use cutting-edge technologies to be meaningful to someone. I hope that even in this in-between place, whether you’re involved in a groundbreaking pilot or an under-resourced institution, you’ll find interesting, creative work to do, something that helps others find the information they’re looking for - and that you’ll see yourself as part of this fragile, revisable, and diverse common world we’re all making daily.
Thank you.
Ruth Kitchin Tillman works on discovery, the library catalog, and linked data projects at Penn State, where she currently holds the Sally W. Kalin Early Career Librarianship for Technological Innovations. She got her start in libraries in Technical Services, spending much of her 20s as the Serials Specialist at Jacob Burns Law Library, only 10 blocks away from where we are today. She received her MLS from the University of Maryland in 2013 and worked as the metadata librarian and ad-hoc cataloger at the NASA Goddard Library and the Digital Collections Librarian at the University of Notre Dame, before joining Penn State Libraries as the Cataloging Systems and Linked Data Strategist, 5 years ago this fall. Her research focuses on library systems, the people who maintain them, and the challenges and opportunities in the implementation of linked data.
Footnotes
-
After writing this, I ended up in conversation with a coworker about a period in the early 90s where her campus library’s books had been barcoded and could circulate but weren’t connected to MARC. If someone wanted to know what they had out, the library workers would have to get the barcodes from the computer and look them up in giant binders to get the book’s title. After about a year, the barcodes were all properly appended to catalog records and then the system could retrieve the titles, etc.. This really brought home the importance of metadata snippets! ↩︎
-
This is a big difference in kinds of use cases – sometimes things should be combined and allow you to use subformats. Sometimes they shouldn’t. This is a place where I think automated combination of works doesn’t automate well. ↩︎