MARC Records vs. the Catalog
Abstract
This was presented at the ALA Core Catalog Management Interest Group on March 9, 2022.
What happens when you try to build a new catalog based on the MARC standard? This presentation is a retrospective of experimentation, failure, and compromise in the design of Penn State’s Blacklight Catalog with lessons learned about designing for MARC data in the real world.
You can view the recording from ALA here

Good afternoon, my name is Ruth Kitchin Tillman and I’m going to be presenting MARC Records vs. the Catalog, lessons in Data Quality and User Experience from a project we did to replace the Classic Catalog at Penn State.
My background is primarily in tech services and then metadata/digital collections. When I came to Penn State, I was hired into a role that they still weren’t sure what to do with except that I was going to lead a project to improve discovery in our libraries, or at least try. One of the most exciting parts of the job, for me, was that I was going to be working on a new catalog, which we were spinning up ourselves with Blacklight software.
I’m going to be talking about that catalog project today, specifically about the data — the operational elements of MARC and how these related to my design choices, then what happened when that design met the real world, and some lessons learned. I’ll be leaving time at the end for questions and discussion.

You could say I’m the classic catalog’s number one fan, but that’s only 75% true.
Why? Because most classic catalogs were built two decades or more ago and have changed very little even as the web and the users have changed around them. Sirsi’s E-Library, which fit neatly on top of our Symphony ILS, was session-based so the links weren’t stable and it timed out on you. You might get a message telling you that you couldn’t access it unless you cleared cookies …oh, and the back button didn’t work. Ever.
We built our new catalog using the Blacklight application, which has a lot of the basic catalog features, behaves like a modern website, and can be extended to add new fields and features.
Operational Elements of MARC
Because building catalog index and display from scratch requires a deep dive into thinking about MARC as operational data, I’m going to provide an overview of the operational elements of MARC. These play a role in both my design decisions and the real-world outcomes. I’ll try to make this both high-level enough so as no to overwhelm anyone who’s not got a MARC background and also interesting for those of you who can do this in your sleep.

The MARC standard has five different types of fields.

The most granular called fixed fields. They’re based on field number/type and position. They’re letters or numbers which convey specific meanings and blanks when nothing applies. These were very important when MARC was developed over 50 years ago because we had a lot less disk space available. Sometimes they’re interdependent.
For example, in the 007, position 0 tells you the category of material, like computer file or microform. If it’s a computer file, then position 3 is about color and the value “a” means “one color” — if it’s a microform, then position 3 is positive/negative/mixed aspect and the value “a” means you’re dealing with a positive microform vs. the inverted colors of a negative.

To give a quick example of how much granular data we can get out of a good record, let’s look at a record for one of my favorite video games, Mass Effect’s legendary Edition.

This is a screenshot of our catalog’s MARC view page for that record. On a side note, isn’t it lovely? The top fields above the 019 are the various data fields along with the record ID and an 003 specifying that this is from our SIRSI catalog.
The data tells us that it’s

- a computer file
- a monographic work — which just means it’s a complete thing in itself
- it was published in 2021
- it’s for adults
- it’s stored on a physical medium (which happens to be an Xbox disc but we don’t know this yet)
- it’s a game
- it’s in English
- it was published in California

- it’s an electronic resource
- on an optical disc (so now we know that direct media it was on is an optical disc)
- it’s multi-colored
- it’s a CD/DVD-size disc
- and it’s got sound.
So if you put all this together, you’ve got a colorful game meant for adults, something that’s complete in itself, it’s got sound and is in English, it was published by a California company in 2021, and it’s on an optical disc of CD-ROM size. That doesn’t tell you everything about it, but any of those data points might be useful in searching and faceting.
Of course, while all those data points would let you construct a really specific search, the 655 field “Xbox video games” is a synthesized way to get a lot of the same information and one very important additional detail—the gaming system—in a single data point.

A lot of MARC fields have an indicator between the field number and the field’s data. These are metadata about the MARC fields themselves. They might be necessary to understanding the field, like a 264 requires an indicator to specify whether the data is about publication, production, copyright, manufacture, or distribution.
It might also tell you something for indexing, like that a name is in last name, first name order or how many characters to cut off the front of the title’s data to make an alphabetical title index. It may also tell you about the source of data, like whether a subject came from the Library of Congress’s terms or elsewhere.

Here’s just a few examples of indicators in practice. First, on the 100 field for the author, the first indicator is 1 because the name is in an inverted form — this can be important information for indexing it.
Then because it does have an author field, the first indicator of the 245 is a 1, not a 0 — this is more of a holdover instruction on which catalog cards to print than something we use today.
Then the 264 has a second indicator 1, indicating it’s the publication information. For some records, you’ll also see a 264 field which only contains a copyright date and the indicators are how we can split them out.

Then there’s controlled vocabularies and other codes, which aren’t as granular as the fixed fields and indicators but still support some machine-actionable components. Mostly these allow us to group together everything which has shared controlled values and search within these groups.

Here’s a quick examples. In the 650 fields up top, each of the segments is a controlled value. The constructed subject is the most specific possible value, but by turning it into a segmented search in the display section, we allow for searching by broader controlled values, like all Fire risk assessment in Pennsylvania, not just Pittsburgh.

MARC then has fields that are not controlled but have an expected structure. For example, the title and author statement expect ISBD punctuation like slashes and colons. This means that we don’t have to add extra formatting to display for it to look a certain way. ISSNs keep their hyphens but ISBNs don’t—this affects search. A table of contents may use subfields or just hyphens and slashes to break apart chapter titles and authors’ names.
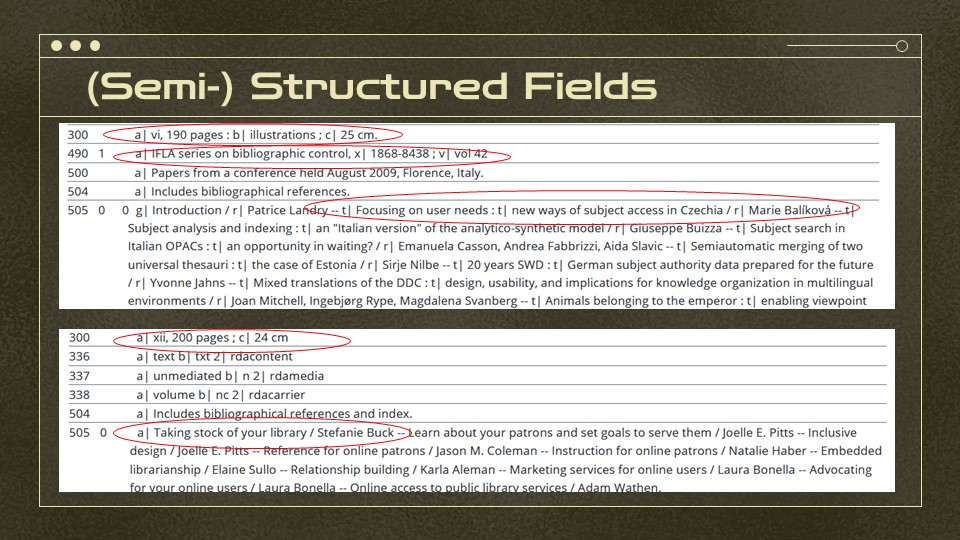
Here’s just a couple examples of semi-structured fields. Most of the time, these can just be displayed as is, but if you want to get something machine-actionable out of them, you may have to prepare to strip off spaces, colorns, commas, etc.
It can be tricky because, one set of these 505s lets us easily distinguish between titles, subfield t and authors, subfield r. The second 505 is all in a single subfield a, although the ISBD formatting in it could be machine processed and will at least display nicely.
And then free text fields are mostly just notes. They aren’t structured enough to do more than index them for keyword search and display them as-is.
Catalog Design
So though we were using software that was meant for catalogs, the project required a lot of design choices about how we were going to use the MARC data.
First: we want to be able to filter by format and media types, but how do we make those determinations?
Should we use the item types from Symphony? Should we use the MARC leader? Both? Should we allow for everything supported by MARC in its full granularity or generalize?
What fields should be searched? How should we group and weight things like titles or creators? Which search boxes should be found where?
Next, one has to decide things like display options — what goes on the search result page? What goes on the item page? should we just display all MARC fields? But then… do we really need to display the 010 or is that more for our own business, especially when Blacklight has a MARC View option.
What about formatting? Which should link to searches for similar items?
We have a public wiki, where I documented most of these decisions and you can check it out.
Data and Indexing
So what should our data look like? and then, to figure out how we get there… what DOES our data look like?

While Blacklight is the front end, what we actually used to create all the data for indexing and display is a program called “Traject” and developed by Jonathan Rochkind for indexing—most importantly, it understands MARC. Don’t worry, this isn’t going to be a code talk, but I wanted to show you how closely the MARC ties into the indexing.
The two examples above are for publication display field and duration display field. In the first, we’re indexing both the 260 and 264, because while the 260 is deprecated, a lot of catalogs have a few 260s lying around. You can see that for the 264, there’s a pipe, a star, a 1, and another pipe. This tells the system only to index 264s with a second indicator 1 and any first indicator (star as a wildcard).
And we’re indexing most valid subfields from each, but we can designate how many we index or choose a function that indexes everything. For duration, or playing time, we there’s only a subfield a, so it’s an extremely neat little thing.

It’s also built to handle things like the specific fields of a MARC leader that tell you more about the record and contains mapping files to make sense of them. This is from the original Traject project — we could then add letters or change labels.

Our devs could also extend the program with new methods for things like — check the 949 m for a library code — here’s the conditions to determine if it’s online, on order, should be skipped, or should be mapped to our library code/library name mapping field, which translates things like an uppercase NEWKEN into Penn State New Kensington

So when designing for the catalog, I made design documents with things like — all fields which have titles and which kinds of titles they are.

then thought through how these titles should be grouped for searching. For example, after we launched the catalog, it became clear that we needed to index the 245a and the 245ab as separate fields and search against them without stemming (which adds plurals and such). Indexing the 245a separately from the 245ab means that we could give it a higher match weight.
This helped solve cases like Hillbilly Elegy where it would show an excellent book about Appalachian responses to Hillbilly Elegy before showing the original book. Why? Because the response book had the term in its 245ab and in a bunch of the 505t (chapter titles) and in the subject field.
Since academic libraries often have books written about other books, we had to teach the catalog “look, when the 245a is an exact match or a really good match to the search term, boost that way up”! Now the response book is the second result, which is appropriate!
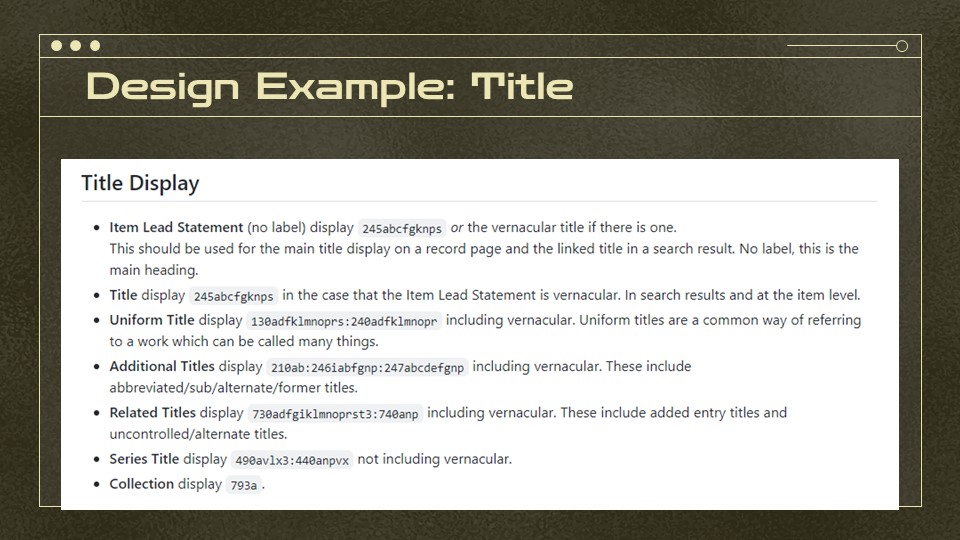
We also had to design things like the title display field — and use Traject’s vernacular option to make sure that if the title were in a non-Latin script like Chinese or Cyrillic, which is encoded a little differently in MARC, it would display first and be followed by the secondary transliterated title.
Design Meets the Real World
Once we implemented the design, all this standard-based modeling met up with the real world. While I tried to anticipate the vagaries of our data, I was no match for what was actually in the catalog.
I’m going to walk through 6 instances where the best of intentions collided with the real world of MARC records. While they’re not the extent of challenges I encountered, they each represent a different type of problem. Each of these is something you almost certainly have in your own catalog.
Not a Novelization
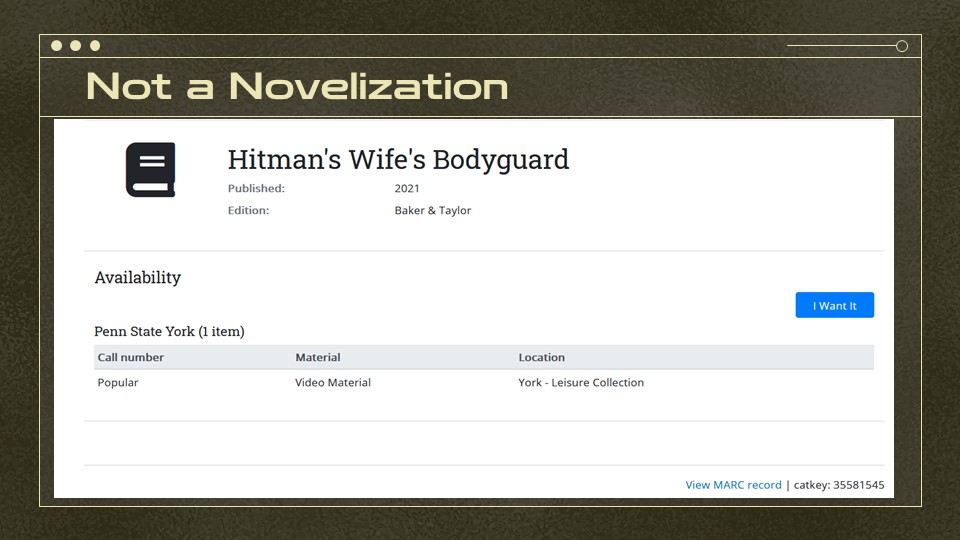
No, this isn’t a novelization of the classic film The Hitman’s Wife’s Bodyguard.
You can see that while the availability section, which is based on a live query to Sirsi Symphony, knows this is a video… the icon is a book. It also facets as a book which means it doesn’t show up for video searches.
So why does it think it’s a book?
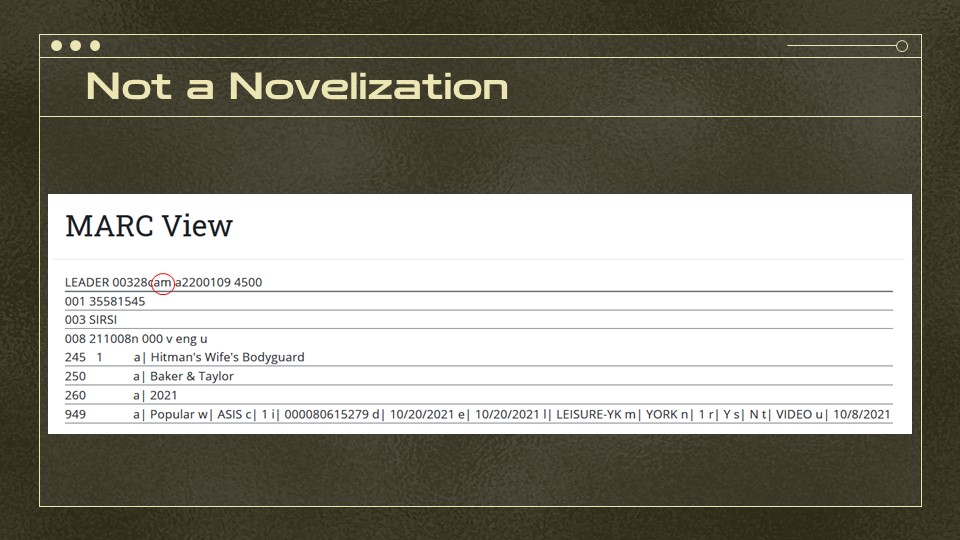
What happened? One cool fact about Penn State Libraries is that any resident of the Commonwealth can use them. So many of our campuses keep a rotating leisure collection of popular books and films. The problem is that we get records like this from vendors and they don’t go through the same kind of cataloging as a DVD we’re planning to keep.
So this is the whole MARC record. And the part I’ve circled? That says it’s a textual monograph… while not all textual monographs are books, our indexer then looks for hints that it’s something more specific like a government document and, if it doesn’t find anything else, it falls back to book.
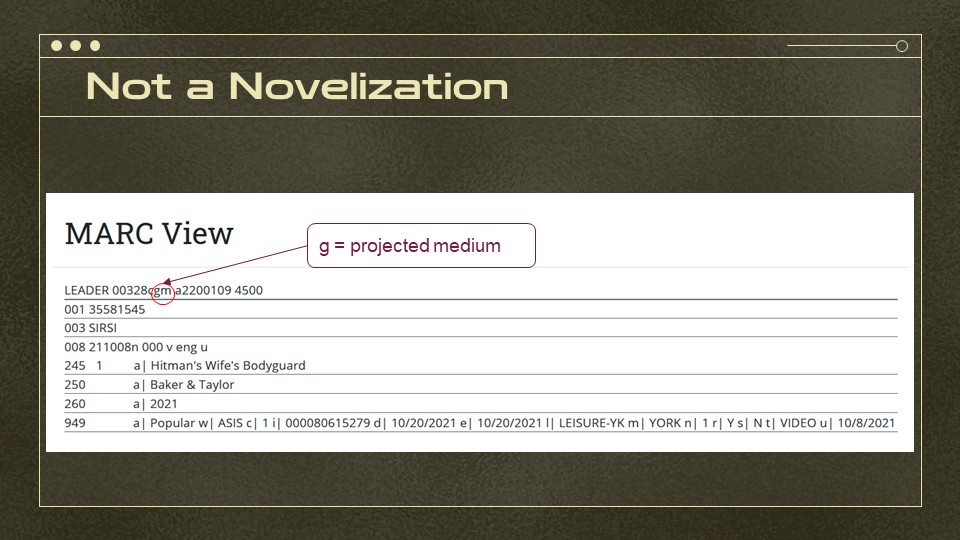
This is what we were expecting. We’ve been trying to remediate these, since the data really is wrong, but it raises the question about the angle of approach I took when determining “type of thing” — what if i’d checked the 949 field and then worked from there? We do use the 949 for some very specific things like Juvenile Books. I didn’t base my indexing on it because I saw it as more dependent on our particular ILS… but that was probably the wrong approach.
Three Unique Shakespeares

Then there are the controlled values that aren’t. If you look for William Shakespeare in our Author Browse search, these are the three forms of his name. … some of you can guess what’s coming next…
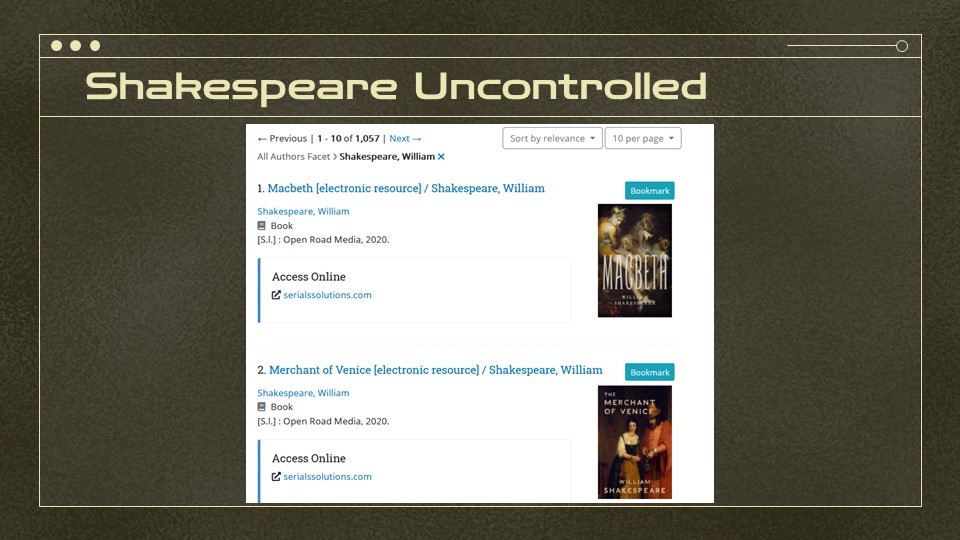
All those simplified forms of his name? Those are vendor records for ebooks. No matter how good the design decisions, if the controlled data isn’t actually controlled, things like the Shakespeare entries will end up grouped separately.
12,000 LPs That Weren’t
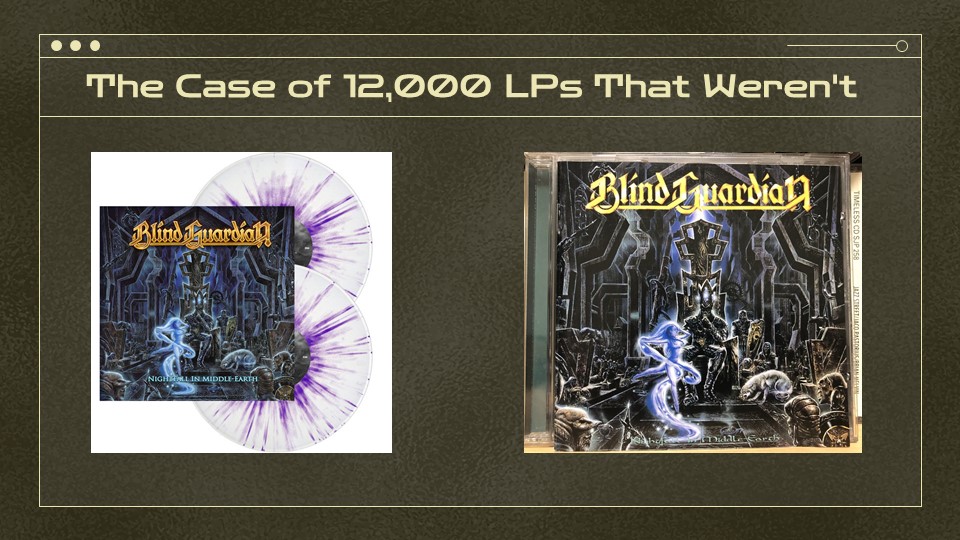
Then there’s the case of the 12,000 LPs that weren’t. Shortly after we brought the catalog online, our music librarian emailed to let us know that she’d found about 12,000 things which said they were LPs but were more often audio CDs or other forms. Because Penn State has a robust collection of LPs we weren’t thrown by the numbers we’d gotten, but it turned out they were almost double what they should’ve been. Some of you might already be diagnosing this from the images I’d chosen.

While repurposing existing records is a time honored tradition, the homegrown system we used in the 90s didn’t let us edit the MARC leader. So what we ended up with was a bunch of records with leaders and fixed fields that declared them LPs.
This was, it turned out… a bad idea. It didn’t affect things until I added this level of granular faceting, but once we started using more of the MARC data it all went sideways.
Because this was one big set of bad data, we were able to use other fields to manually determine that a bunch were CDs (based on physical descriptions, notes, and call numbers). One of our catalogers fixed the main batch and then passed to our AV team to handle all the edge cases, because sometimes more than the leader got left behind during the record recycling. We also found a few odd repurposed ducks like musical scores that thought they were 78s, etc.
No Indicator? No Indexing

As you may recall from the operational elements of MARC, sometimes the indicator is critical to understanding what a field is. This makes a big difference in the 856, for example, where a second indicator 0 means it’s a link to the actual resource, 1 means it’s to a version of the resource, and 2 means it’s a related resource, which can be something completely different!
Unfortunately, while all 856s should have a second indicator, it’s valid for the field to be blank. … initially, we’d just not been indexing these. That was a bad move, I probably should’ve lumped them into related resources. But, as it turned out, we had a bunch of older records which should’ve had a second indicator 0 but were blank.
So, after some consideration, I decided to err on throwing blanks in with 0s.

Just like not indexing them or throwing them in with related resources, this wasn’t an automatic fix to the problem. While a lot more good links showed up in our access online box, you can cue the viral Tiktok “oh no” music for some of the other outcomes.
That? That is a link to a Robert Heinlein fan page, an “online archive” (where archive is used loosely).
Digital Collection Duds

Speaking of links, we also built a nice, specialized display which detects links to items held in our digital collections and generates this box instead of the plain “Access online” one above.
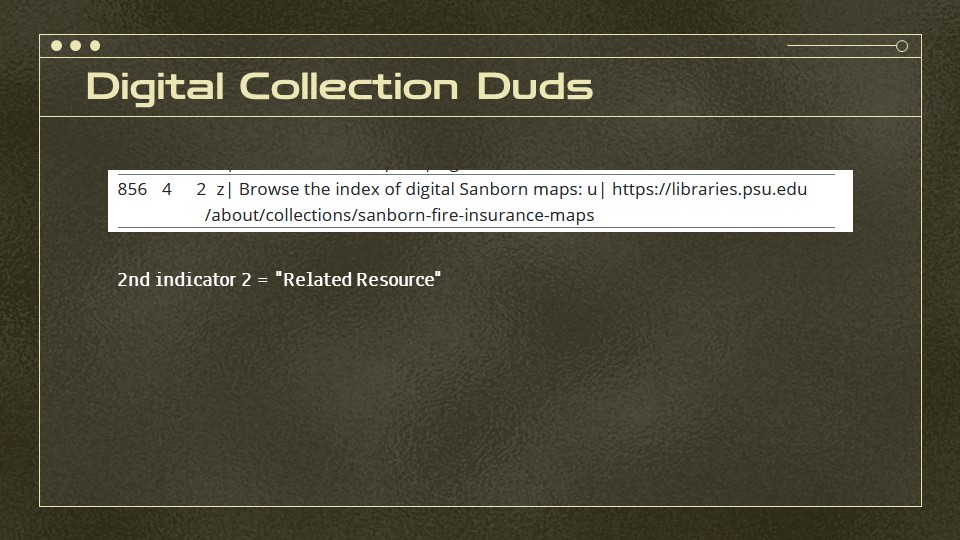
Someone then asked — but why aren’t they showing up on records for our awesome collection of Sanborn maps, many of which are digitized. Well, as it turned out, these all had links to the collection vs. to the map itself. This means second indicator is “2”. … which is related resource.
Since our tests for digital collections only applies to actual resource or version of resource links AND since our box’s language indicates that you’ll be looking at the item, we were stuck with a couple options.
First, we could fudge the data and change the indicators. That seemed… not great.
Second, we could write some specific code for this collection. On the one hand, that’s tempting because this is one of our really good collections — on the other, there’s a big difference between programming at the level of “apply this to all links to our digital collections platforms” and “apply this to all links to our Sanborn collection.” How specific do we want to be? How many exceptions do we want to manage?
For now, we’ve gone with the third option. Since we’ve just brought a new ARK server online, it may be feasible to eventually link to all of these — and the ARK syntax will be added to our list of digital collections URLs — but that’s going to take some time. So we’re missing out on a highlight box, but we’re not adding exceptions upon exceptions.
Linguistic Confusion
And finally, I don’t have a screenshot for this because I managed to avoid it after seeing it in other people’s catalogs. There’s several Blacklight catalogs where you’ll get some very strange film results when searching by language. For example, why did a search for DVDs in Spanish inredacted’s catalog return the 2021 Dune?

Because sometimes MARC itself and general MARC practices are the problem. The 041 field of that DVD has three subfield “a"s — the field for the main language of the item. Why? Because it’s got French and Spanish dubs as well as English. When the item is a book or an audio CD? that means it’s actually in those languages. But for videos, there is no separate subfield for dubbed languages, so they end up in the subfield a. So what works well for some kind of resources goes wildly off the rails for others.
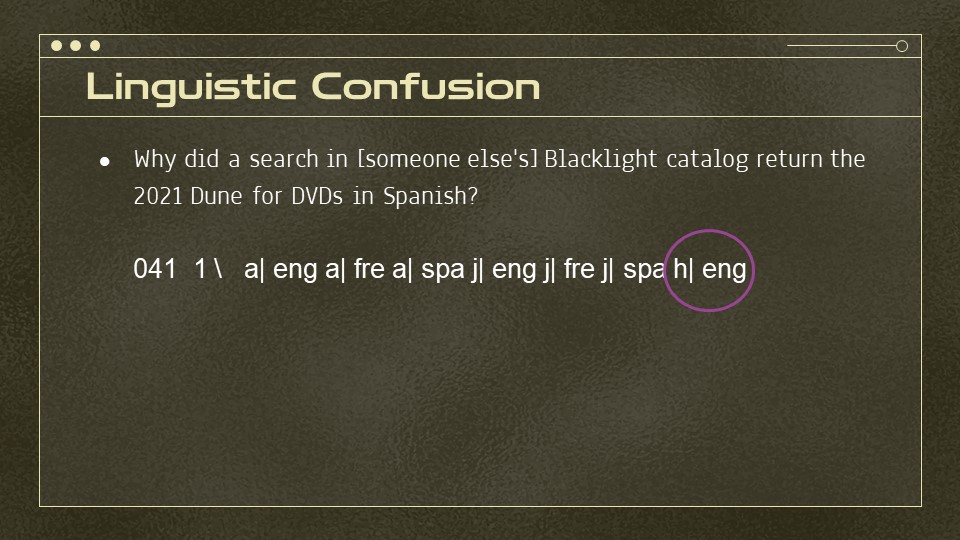
There is actually something that might work for this, which is the subfield h or the original form of the work. The complexity here, though, is that this also only works for certain kinds of materials.

as I’m sure some folks were already thinking - - but translations! If you have a book that’s an English translation of Hye-Young Pyun’s novel, The Hole? You wouldn’t want to index its language as Korean. Similarly, while most mainstream films come with a standard set of dubbed languages, you might have something like a Japanese anime dubbed into English on a DVD that doesn’t include the Japanese language track.
Lessons Learned
So now I’m going to talk about three lessons learned from this work and we’ll have time after for Q&A and discussion
1. Build From Simplest to Most Complex

A recurring theme when things went wrong was my focus on the complex possibilities of MARC. When data accuracy and data completeness are in question, I’ve learned it’s wiser to to build from the simplest use case to the most complex.
For example, the simplest assumption would be that the item types attached to a record reflect the kinds of materials on the record. Based on my experience in the last 3 years, that’s not entirely true, but it’s more often accurate than the leader. A video could just be a video — but so could an online resource with video info in its leader. For complex format logic like a government document, we already have a decision tree of government document tests which we could add to things that could be government documents—books, serials, microforms, etc.
Similarly, I could’ve written the indexing logic for 856s to index all 856s with first indicator 4 as resource links unless the second indicator was 1, 2, (or 8) vs. setting them up as separate if statements which excluded blanks.
2. Solve Data Problems As Data

This leads into the next point — what about irrelevant points like the Heinlein link? As a rule, data problems should still be solved AS data problems. Those 12,000 not-LPs? That was a massive data problem, something that should be changed. That one link? Unfortunately, some data have to be solved individually, though we might turn reviewing the 856s without second indicator that into an at-home project in the future.
The balancing act between this point and the first one is lies in determining whether a data problem can be solved by a logic choice that works better for everything or whether you’re adding more complex logic to handle edge cases that are caused by bad data. For example, starting with Video item types for videos would’ve saved us from fixing vendor records for things that aren’t from our permanent collection and, probably, would’ve been just as efficient for other video indexing. So, should we change it? A lot of that depends on whether the folks who will make that change have time and capacity for that change now — if I were designing format logics now, I would approach differently, but with it working for good data, the developers’ time is probably better spent working on adding more features/fixing bugs that aren’t caused by data.
3. Satisficing - or Making Peace

And finally, satisficing — kind of. Technically, satisficing means going for the minimum satisfactory condition or outcome. I want to more than that, but part of this work involves making peace with one’s inability to fix everything, where that’s data or design.
We didn’t add an edge case to make the Sanborn maps related link stand out better, though we’ll be improving overall link display a little in the coming months.
We have over 1000 records in which William Shakespeare’s name authority is Shakespeare, William with no dates — these all come from vendors. A patron who clicks to see more works by that Shakespeare will miss the 4800 records with the real Shakespeare’s name authority and vice versa. Unless vendors substantially improve their records, or we hire 4 more highly-skilled batch data workers just for ongoing data cleanup, that kind of thing won’t change.
Even then, sometimes fields like the 041s, as I showed earlier, just aren’t used in a consistent enough way that we could make them machine-actionable.
And I’m sure that someone else will email us in the next week about another weird edge case that I haven’t yet encountered, a bad link, or an individual musical score that thinks it’s a 78.
Conclusion
We will never have the perfect, data-driven catalog of my dreams. But I hope that what I’ve shared and our conversation that follows help others think through their own projects working with catalog records, whether MARC or BIBFRAME, and really any kind of project where the completeness and accuracy of the data is uneven.