Learning Cell Cross in OpenRefine
Abstract
This written tutorial and prerecorded demo are derived from a 1-hour webinar held on March 26, 2020.
Sometimes, when working with spreadsheet data, you need to get one or more values from spreadsheet A into spreadsheet B, matching them with the correct row. There are several ways you can do that, but one of the easiest I’ve found is to use OpenRefine and “Cell Cross.” It’s kind of what it sounds like – cross-referencing between OpenRefine projects.
OpenRefine uses Google Refine Expression Language (GREL). It’s very powerful, but is a little different than most languages (SQL, Python, etc.) which you might already use for data manipulations. In this demo, I hope to make it a little more familiar.
View Demo on YouTube
Watch a video of the walkthrough below:
Sample Project
For the demo, I’ve designed a simple project. Suppose you want to add a finding aid link to each of your MARC records. You have one spreadsheet which tracks all your ArchivesSpace projects and has the project’s ASpaceID, title, extent, and URL in it. You’ve got a second sheet which matches your ASpaceIDs (as archivesID) and your catalog IDs for MARC records (as catkey).
I’ve created sample data below which you can download and use yourself in OpenRefine. When doing a Cell Cross, you’ll need both sheets imported into OpenRefine and to know their project names and column names. I tend to keep them open in two separate Firefox tabs so I can review them.
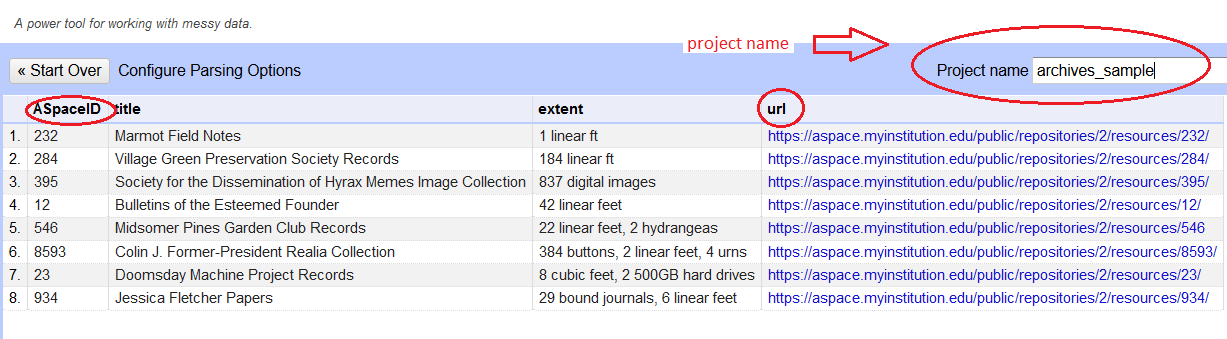
Sample Data
You can download the sample data to test it yourself:
- archives_sample.csv
- key_match_sample.csv
- old_fa_urls.csv (used in the last example at the bottom)
One note: while I’m matching IDs in this demo, you can match any two things with, well, match. That can include long test strings, place names, or even LCSH subjects formatted like “Quilting–History.” You may need to manipulate the sheets so your data does match, but that’s another of OpenRefine’s strengths and can be found in other tutorials.
Archives Sample
Key Match Sample
| catkey | archivesID |
|---|---|
| 3935823 | 232 |
| 3942352 | 12 |
| 93525335 | 8593 |
| 8643413 | 4302 |
| 3953838 | 934 |
| 39582803 | 546 |
| 490235223 | 13 |
| 9382124 | 395 |
| 29483520 | 23 |
| 928423523 | 932 |
Performing Cell Cross
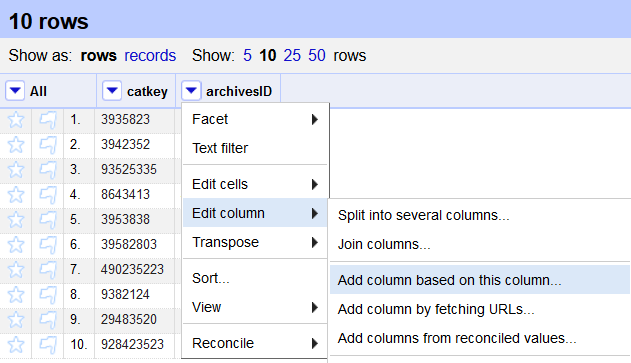
Navigate to the project where you want to add new data (in this case, project key_match_sample).
Select the drop-down in the column you want to match (in this case, archivesID). Choose Edit Column -> Add Column Based on This Column.
If the column is an ID, for example, now you have to find/match that same ID in your second project. Format your cell cross statement as follows, where otherProject, columnToMatch, and columnToAdd represent variables:
cell.cross(otherProject, columnToMatch)[0].cells[columnToAdd].value
In this case, that looks like:
cell.cross("archives_sample", "ASpaceID")[0].cells["url"].value
(note the quotes)
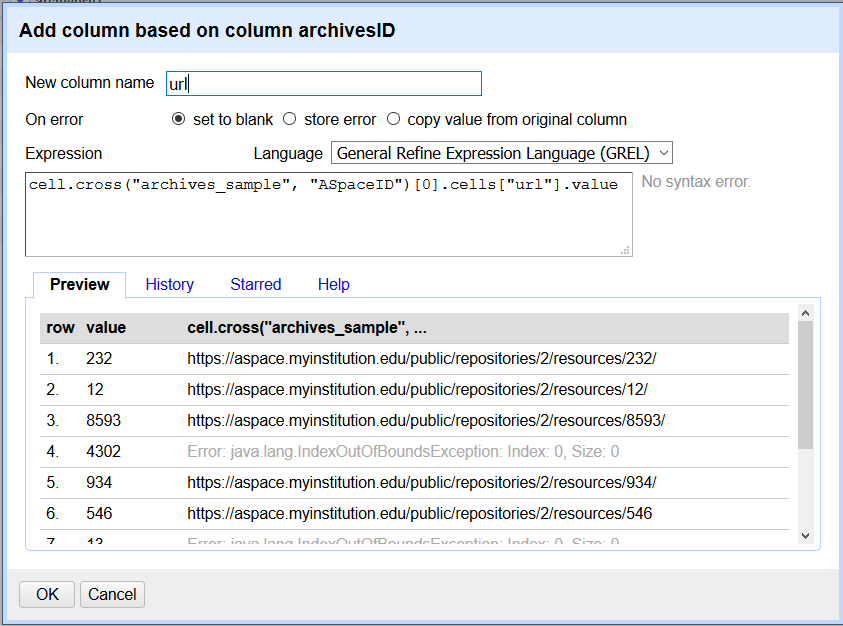
Broken down, that can be read as “in the project archives_sample, match the value of each row in the source column (project: key_match_sample, column: archivesID) with a row in column ASpaceID. If such a match exists, then fill the new column with the value for the field url from that same row.”
The preview window shows a snapshot of the results you’ll get. As you can see, most things have a match and the URLs look good!
For now, just ignore the [0]. In this case, it makes your new data appear as one value instead of an array with one value. If you’re expecting more than one row in the other spreadsheet to match, experiment with removing this to view it as an array.
On Error or No Match
What happens if there’s no match? Or what if we don’t know whether the spreadsheets have 100% overlap? Maybe we have all the catkeys and archivesIDs, but we only have URLs for the records which are published. Maybe we’re trying to match our circulation count spreadsheet with a spreadsheet of consortial holdings. We’re using the OCLC number, which works most of the time but sometimes there’s no match. Maybe we have the old OCLC number.

Fortunately, OpenRefine offers an “On error” choice. I chose “set to blank.” You can then do whatever you need with the rows which do or don’t match.
You can add as many columns as you want this way. You can use it to pull together major components of several spreadsheets based on a shared value or values. You can even pull data across more than the 2 projects as shown below.
Extending the Data
Suppose you have another project in which you have your old finding aid URLS and catkeys for their respective MARC records. It might look like something like the below:
| catkey | old finding aid url |
|---|---|
| 3935823 | https://findingaids.mylibrary.edu/935.html |
| 39582803 | https://findingaids.mylibrary.edu/25.html |
| 29483520 | https://findingaids.mylibrary.edu/742.html |
You want to set up redirects from your old finding aid site, but you need to pair the old and new URLs. Since you’ve now got a copy of key_match_sample which contains catkeys and ASpace URLs (even if you deleted the archives IDs), you can build on that with this data.
Using the technique above, you could add a new column to the project, based on the catkey column, and bring over every new finding aid URL if it exists. Let’s suppose the project is named old_fa_urls. Your cell cross would be based on the catkey column in key_match_sample and look like:
cell.cross("old_fa_urls", "catkey")[0].cells["old finding aid url"].value
In this case, the based-on column and the matching column in the other spreadsheet are both named catkey. This doesn’t cause a conflict, but it’s a reminder to keep tract of your project and column names.
You could then export key_match_sample as a spreadsheet from OpenRefine, delete the catkey and archivesID columns, and ask the person handling your site to set up redirects from https://findingaids.mylibrary.edu/935.html to https://aspace.myinstitution.edu/public/repositories/2/resources/232/, for example.